Méthodologie adoptée
L’Observatoire a mis en place une démarche méthodologique pour l’obtention d’une base de données centralisée, de bonne qualité et avec des marges d’erreur acceptables, à partir des bases de données reçues de ses différents partenaires.
Cette démarche méthodologique repose sur :
1. La collecte, le traitement et le stockage des données
La constitution de la base de données consolidée suit une approche graduelle et itérative depuis la réception des données jusqu’à la production des indicateurs.
Ce processus débute par un travail de cadrage des données et de spécification des besoins, réalisé en collaboration avec chaque fournisseur de données, afin d’appréhender la donnée et de définir les populations étudiées, en plus d’assurer un premier niveau de conformité des bases reçues.
Lors de la réception des bases de données, des analyses qualitatives sont effectuées afin d’évaluer la qualité et le potentiel d’exploitation des données (taux de remplissage des identifiants et des autres champs, taux de doublons, etc.). Ces analyses permettent également de définir les prétraitements à effectuer sur ces bases (traitement des doublons, création de nouveaux champs et normalisation des champs).
A partir de l’évaluation des taux de remplissage de chacun des identifiants disponibles (Identifiant Commun des Entreprises ICE), Identifiant Fiscal, RC/Code Tribunal et N° CNSS), un processus de croisement employant ces identifiants est utilisé pour que la fusion des bases s’accomplisse de manière optimale et fiable, sans perte d’informations ni présence de doublons. Il est complété par d’autres traitements, à travers l’application des règles de gestion et l’enrichissement des données.
En aval de ce processus, des bases centralisées sont créées, garantissant les principes régissant la constitution des bases de données et de production d’indicateurs, à savoir l’unicité de la représentation d’une entreprise dans ces bases, son caractère actif et sa description avec la meilleure qualité d’information possible.
2. Analyse et diffusion
Une fois la Base Consolidée créée et prête à être exploitée pour le calcul des indicateurs, une analyse de la qualité est effectuée pour la définition des périmètres de calcul. Un référentiel est créé à cette fin, définissant en détail les indicateurs, leurs méthodes de calcul, leur interprétation ainsi que leur périmètre d’étude.
Suite à la production des indicateurs, ces derniers sont cadrés par des grandeurs macroéconomiques et comparés avec les tendances nationales et internationales. Dans le cadre de l’enrichissement et de la mise à jour de la liste des indicateurs à produire, l’Observatoire effectue une veille continue sur les études et publications nationales et internationales.
3. Stratégie de fiabilisation des données
Dans le cadre de sa méthodologie, l’Observatoire a mis en place une stratégie de fiabilisation des données sur 5 niveaux, reposant sur des processus pluriannuels de qualification des données qui s’articulent autour du recensement et la fiabilisation de la population des entreprises afin d’utiliser l’information disponible la mieux qualifiée dans chacune des bases, de compléter les informations manquantes autant que possible et d’assurer l’unicité de l’entreprise avec une forte probabilité en vue d’éliminer les biais dans les calculs liés à laprésencede doublons.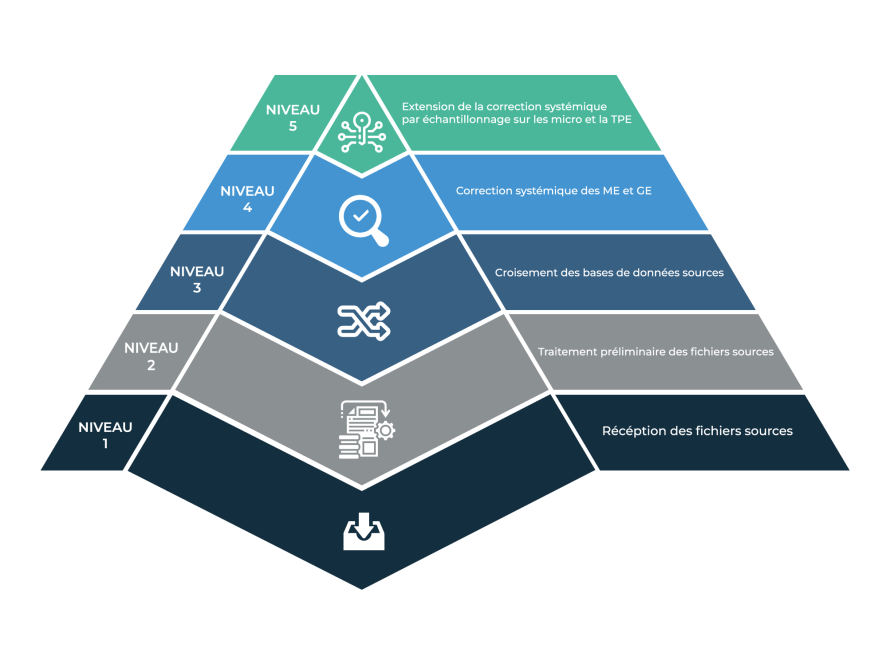
Défis rencontrés
Au niveau de la collecte et du traitement des données, l’Observatoire a identifié et traité plusieurs difficultés techniques liées à :
- L’absence d’une clé commune d’identification ayant engendré une complexité dans les opérations de croisement et de fusion des bases de données, étant donné que l’ICE (Identifiant Commun de l’Entreprise) est en cours d’implémentation ;
- La structure des bases de données reçues, destinées aux missions propres à chaque organisme, ne permet pas leur exploitation à des fins d’analyses décisionnelles ;
- L’utilisation de référentiels non standardisés propres à chaque institution ;
- L’utilisation de nomenclatures différentes dans la codification des activités des entreprises ;
- La non-fiabilité de certains champs, la multitude de données manquantes et la redondance des données.
Par ailleurs, l’accès aux données relatives aux entreprises reste encore relativement limité. Avec ses partenaires, l’Observatoire plaide pour davantage de décloisonnement des données du gouvernement et ce, dans le respect de la confidentialité des données personnelles et de l’ensemble des législations qui cadrent le traitement de la donnée.
En effet, le décloisonnement des données du gouvernement représente un gage de transparence qui influe positivement sur les rangs des pays dans les classements internationaux en matière de compétitivité et leur permet de gagner des points de PIB. En effet, les données sont perçues comme étant le vecteur d’une information publique de meilleure qualité, qui contribue à l’amélioration du climat des affaires d’un pays.
Cadre technique et scientifique
La data science comme levier d’innovation pour le développement de la TPME
L’exploitation des données sur l’entreprise est un outil majeur au service des stratégies de développement de la TPME. En effet, les « Big Data », l’intelligence artificielle, la transformation des chaînes de valeur, les stratégies et les organisations fondées sur la « culture de la donnée » et de la transparence, caractérisent les formes actuelles de la révolution numérique et permettent de mieux exploiter le potentiel de croissance et d’innovation des entreprises.
La révolution numérique facilite la production, la diffusion et le traitement de données de masse. L’ouverture et le partage de ces données sont devenus un puissant levier pour :
- Renforcer la confiance des entrepreneurs et des investisseurs grâce à une plus grande transparence de l’action publique ;
- Permettre et soutenir la création de services innovants dans l’accompagnement des entreprises ;
- Améliorer l’efficacité des programmes de soutien de l’Etat envers les entreprises et construire des outils utiles au pilotage de ces programmes ;
- Soutenir le dynamisme économique, en créant de nouvelles ressources pour l’innovation et la croissance ;
- Créer une dynamique de recensement de la donnée et de structuration de l’écosystème de sa réutilisation dans le cadre de travaux d’analyse et de recherche (administration, chercheurs, universitaires, startups, associations, etc.)
Afin de bénéficier de cette transformation rapide, l’Observatoire compte renforcer sa coopération avec le monde universitaire et de la recherche et mène une réflexion pour se doter d’un collège regroupant des experts dans le domaine technologique, des spécialistes de la data science, des juristes, des économistes, etc.
Techniques de Data Science utilisées par l’Observatoire
L’Observatoire Marocain de la TPME a érigé la Data Science en tant que principal levier de son action et de ses missions, à savoir la production d’indicateurs et de statistiques avec le meilleur niveau de fiabilité possible et avec des marges d’erreur acceptables.
Parmi les techniques de Data Science utilisées par l’Observatoire, l’on retrouve :
Le Machine Learning : qui emploie des algorithmes statistiques ou encore des réseaux de neurones. Les performances d’un algorithme de Machine Learning sont améliorées au fur et à mesure de son apprentissage sur les données qu’il traite, ce qui est possible grâce à l’énorme progrès des capacités de calcul et de stockage.
Le Text Mining : qui consiste à analyser des ensembles de documents textuels afin de capturer les concepts et thèmes-clés, et de relever les relations et les tendances cachées. Il permet ainsi de transformer un texte en données structurées. Le Text Mining classifie automatiquement les textes par sentiment dégagé, sujet ou intention.
Le Web Scraping : porte sur l’extraction de données à partir de sites Internet pour ensuite les enregistrer et les analyser. Le Scraping peut être manuel ou automatique : le premier désigne le fait de copier et d’insérer manuellement des informations et des données, alors que le second utilise un logiciel ou un algorithme qui explore plusieurs sites Internet afin d’en extraire les informations souhaitées. Dans le cas de l’Observatoire, les données extraites sont publiques et librement accessibles par des tiers sur le web.
Mise en place des fondements de l’industrialisation et de l’automatisation des productions
En 2020, l’Observatoire a jeté les bases du système d’information décisionnel destiné à renforcer ses capacités techniques. En effet, le SID permettra à l’OMTPME de disposer des fondements technologiques nécessaires à l’industrialisation et au développement futur de ses activités, en mettant en place une « data factory » pour l’automatisation de l’ensemble de la chaîne de valeurs, de la réception des données jusqu’à leur visualisation et leur utilisation.